译:不要构建多智能体 (Multi-Agents)
原文: https://cognition.ai/blog/dont-build-multi-agents
作者: Walden Yan
译者: Gemini 2.5 Pro
Frameworks for LLM Agents have been surprisingly disappointing. I want to offer some principles for building agents based on our own trial & error, and explain why some tempting ideas are actually quite bad in practice.
用于构建 LLM Agent 的框架出人意料地令人失望。我想基于我们自己的不断试错,分享一些构建 Agent 的原则,并解释为什么一些看似诱人的想法在实践中其实非常糟糕。
上下文工程的原则
We’ll work our way up to the following principles:
- Share context
- Actions carry implicit decisions
Why think about principles?
我们将逐步引出以下原则:
- 共享上下文
- 行动承载着隐性决策
为什么要思考原则?
HTML was introduced in 1993. In 2013, Facebook released React to the world. It is now 2025 and React (and its descendants) dominates the way developers build sites and apps. Why? Because React is not just a scaffold for writing code. It is a philosophy. By using React, you embrace building applications with a pattern of reactivity and modularity, which people now accept to be a standard requirement, but this was not always obvious to early web developers.
HTML 于 1993 年问世。2013 年,Facebook 向世界发布了 React。如今已是 2025 年,React(及其后继者)主导了开发者构建网站和应用的方式。为什么?因为 React 不仅仅是一个编写代码的脚手架,它是一种哲学。通过使用 React,你就接受了以一种响应式和模块化的模式来构建应用,人们现在已将此视为标准要求,但这对于早期的 Web 开发者来说并非一目了然。
In the age of LLMs and building AI Agents, it feels like we’re still playing with raw HTML & CSS and figuring out how to fit these together to make a good experience. No single approach to building agents has become the standard yet, besides some of the absolute basics.
在 LLM 和构建 AI Agent 的时代,感觉我们仍在使用最原始的 HTML 和 CSS,还在摸索如何将它们组合起来以创造良好的体验。除了某些最基础的方法外,还没有任何一种构建 Agent 的单一方法成为标准。
In some cases, libraries such as https://github.com/openai/swarm by OpenAI and https://github.com/microsoft/autogen by Microsoft actively push concepts which I believe to be the wrong way of building agents. Namely, using multi-agent architectures, and I’ll explain why.
在某些情况下,像 OpenAI 的 https://github.com/openai/swarm 和微软的 https://github.com/microsoft/autogen 这样的库,正在积极推广一些我认为是构建 Agent 的错误方式的概念。也就是使用多智能体架构 (multi-agent architectures),我稍后会解释原因。
That said, if you’re new to agent-building, there are lots of resources on how to set up the basic scaffolding [1] [2]. But when it comes to building serious production applications, it’s a different story.
话虽如此,如果你是构建 Agent 的新手,有很多资源可以教你如何搭建基本的脚手架 [1][2]。但当涉及到构建严肃的生产级应用时,情况就完全不同了。
构建长时运行智能体的理论
Let’s start with reliability. When agents have to actually be reliable while running for long periods of time and maintain coherent conversations, there are certain things you must do to contain the potential for compounding errors. Otherwise, if you’re not careful, things fall apart quickly. At the core of reliability is Context Engineering.
让我们从可靠性说起。当 Agent 需要在长时间运行时保持可靠,并维持连贯的对话时,你必须做一些事情来控制潜在的复合错误。否则,如果你不小心,事情很快就会分崩离析。可靠性的核心是上下文工程 (Context Engineering)。
Context Engineering
In 2025, the models out there are extremely intelligent. But even the smartest human won’t be able to do their job effectively without the context of what they’re being asked to do. “Prompt engineering” was coined as a term for the effort needing to write your task in the ideal format for a LLM chatbot. “Context engineering” is the next level of this. It is about doing this automatically in a dynamic system. It takes more nuance and is effectively the #1 job of engineers building AI agents.
上下文工程 (Context Engineering)
到了 2025 年,市面上的模型已经极其智能。但即使是最聪明的人,如果缺乏任务的上下文,也无法有效地完成工作。“提示词工程” (Prompt engineering) 这个词被创造出来,指的是为 LLM 聊天机器人以理想格式编写任务所需的努力。“上下文工程” (Context engineering) 是它的下一个层次。它关乎在一个动态系统中自动地完成这件事。它需要更精细的处理,并且实际上是构建 AI Agent 的工程师们的首要工作。
Take an example of a common type of agent. This agent
- breaks its work down into multiple parts
- starts subagents to work on those parts
- combines those results in the end
以一种常见的 Agent 为例。这种 Agent 会:
- 将工作分解为多个部分
- 启动子智能体 (subagent) 来处理这些部分
- 最后将结果合并
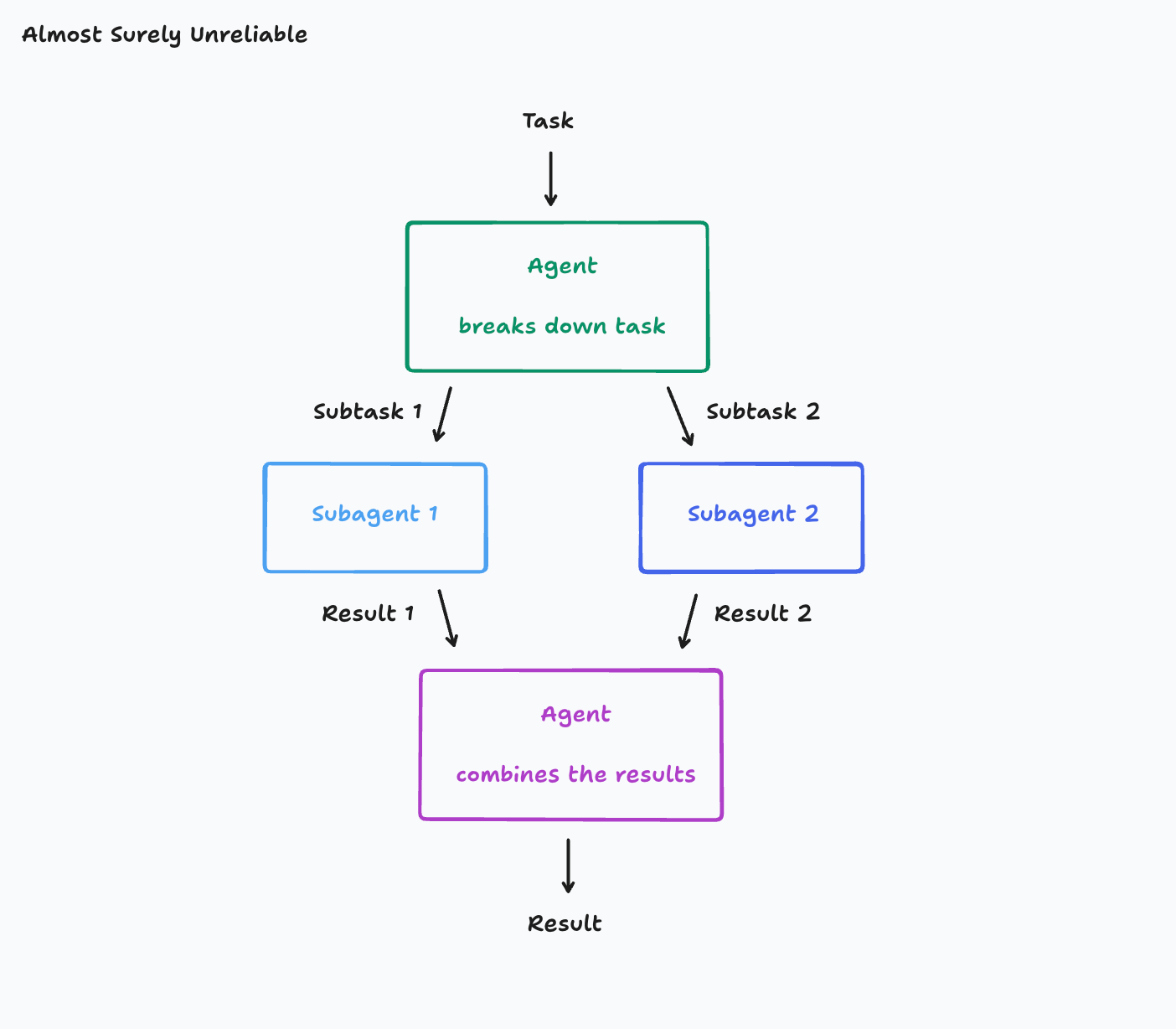
This is a tempting architecture, especially if you work in a domain of tasks with several parallel components to it. However, it is very fragile. The key failure point is this:
这是一个诱人的架构,特别是如果你处理的任务领域包含多个并行组件。然而,它非常脆弱。关键的失败点在于:
Suppose your Task is “build a Flappy Bird clone”. This gets divided into Subtask 1 “build a moving game background with green pipes and hit boxes” and Subtask 2 “build a bird that you can move up and down”.
It turns out subagent 1 actually mistook your subtask and started building a background that looks like Super Mario Bros. Subagent 2 built you a bird, but it doesn’t look like a game asset and it moves nothing like the one in Flappy Bird. Now the final agent is left with the undesirable task of combining these two miscommunications.
假设你的任务是“做一个 Flappy Bird 的克隆版”。任务被分解为子任务 1“制作一个带有绿色管道和碰撞箱的移动游戏背景”和子任务 2“制作一只可以上下移动的小鸟”。
结果,子智能体 1 实际上误解了你的子任务,开始制作一个看起来像超级马里奥兄弟的背景。子智能体 2 给你做了一只鸟,但它看起来不像游戏素材,而且其移动方式也与 Flappy Bird 中的完全不同。现在,最终的 Agent 只好面对这个棘手的任务:将这两个沟通不畅的产物合并起来。
This may seem contrived, but most real-world tasks have many layers of nuance that all have the potential to be miscommunicated. You might think that a simple solution would be to just copy over the original task as context to the subagents as well. That way, they don’t misunderstand their subtask. But remember that in a real production system, the conversation is most likely multi-turn, the agent probably had to make some tool calls to decide how to break down the task, and any number of details could have consequences on the interpretation of the task.
这可能看起来有些牵强,但大多数真实世界的任务都包含多层细微之处,都可能被误解。你可能会想,一个简单的解决方案是把原始任务也作为上下文复制给子智能体。这样,它们就不会误解自己的子任务了。但请记住,在一个真实的生产系统中,对话很可能是多轮的,Agent 可能需要进行一些工具调用来决定如何分解任务,任何细节都可能影响对任务的解读。
Principle 1
Share context, and share full agent traces, not just individual messages
原则 1
共享上下文,并且要共享完整的 Agent 轨迹,而不仅仅是单个消息
Let’s take another revision at our agent, this time making sure each agent has the context of the previous agents.
让我们再次修改我们的 Agent,这次确保每个 Agent 都拥有前序 Agent 的上下文。
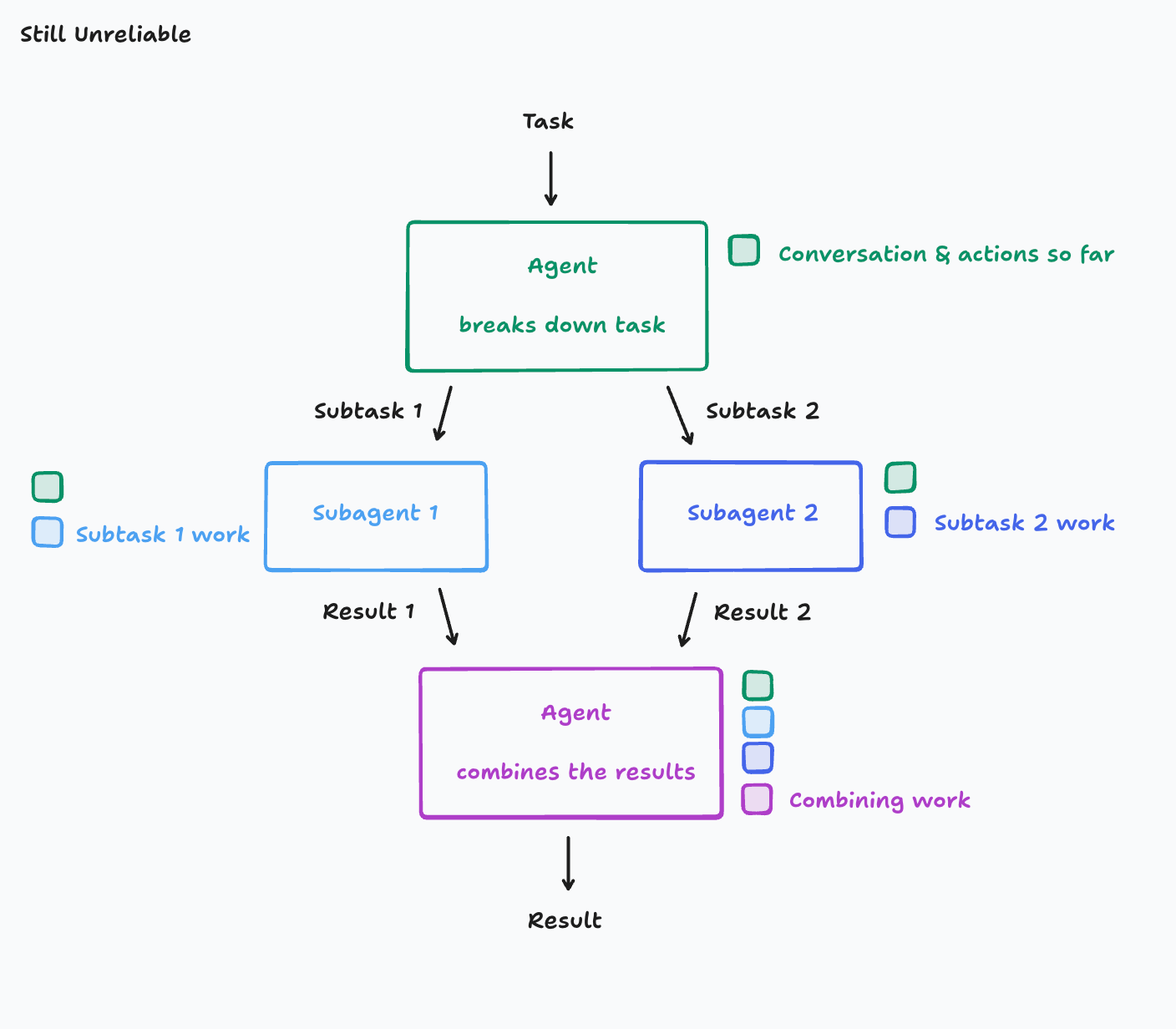
Unfortunately, we aren’t quite out of the woods. When you give your agent the same Flappy Bird cloning task, this time, you might end up with a bird and background with completely different visual styles. Subagent 1 and subagent 2 cannot not see what the other was doing and so their work ends up being inconsistent with each other.
不幸的是,我们仍未走出困境。当你给 Agent 同样的 Flappy Bird 克隆任务时,这一次,你可能会得到一只鸟和一个背景,但它们的视觉风格完全不同。子智能体 1 和子智能体 2 看不到对方在做什么,因此它们的工作成果最终会相互不一致。
The actions subagent 1 took and the actions subagent 2 took were based on conflicting assumptions not prescribed upfront.
子智能体 1 和子智能体 2 的行动是基于事先没有规定的、相互冲突的假设。
Principle 2
Actions carry implicit decisions, and conflicting decisions carry bad results
原则 2
行动承载着隐性决策,而相互冲突的决策会导致糟糕的结果
I would argue that Principles 1 & 2 are so critical, and so rarely worth violating, that you should by default rule out any agent architectures that don’t abide by then. You might think this is constraining, but there is actually a wide space of different architectures you could still explore for your agent.
我认为,原则 1 和原则 2 至关重要,极少值得去违背,以至于你应当默认排除任何不遵守它们的 Agent 架构。你可能觉得这是一种限制,但实际上,你仍然有广阔的空间去探索适用于你的 Agent 的不同架构。
The simplest way to follow the principles is to just use a single-threaded linear agent:
遵循这些原则最简单的方法就是使用单线程的线性 Agent:

Here, the context is continuous. However, you might run into issues for very large tasks with so many subparts that context windows start to overflow.
在这里,上下文是连续的。然而,对于子任务非常多的大型任务,你可能会遇到上下文窗口溢出的问题。
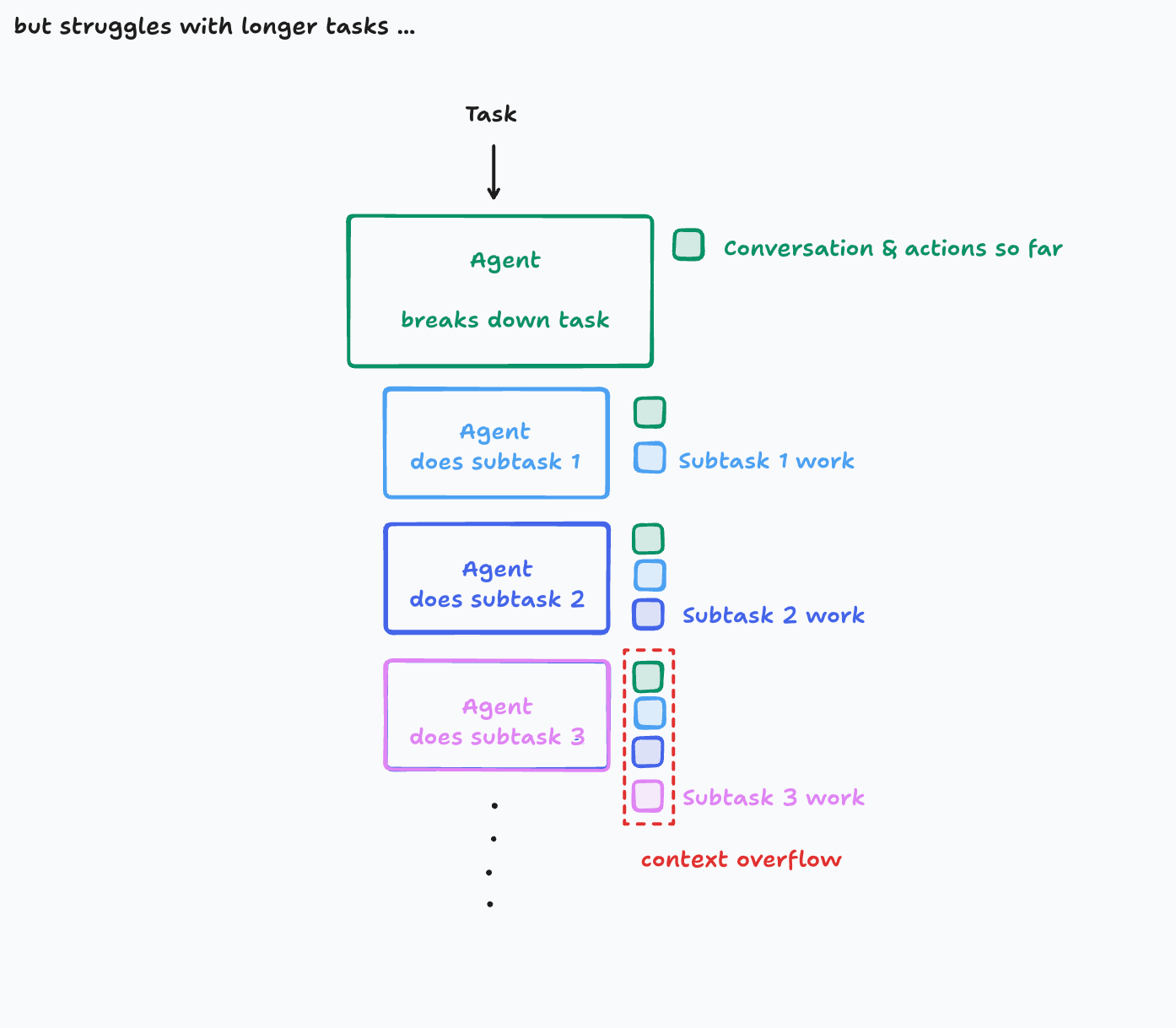
To be honest, the simple architecture will get you very far, but for those who have truly long-duration tasks, and are willing to put in the effort, you can do even better. There are several ways you could solve this, but today I will present just one:
老实说,这个简单的架构能让你走得很远。但对于那些任务持续时间真的很长,并且愿意投入精力的人来说,你们可以做得更好。有几种方法可以解决这个问题,但今天我只介绍一种:
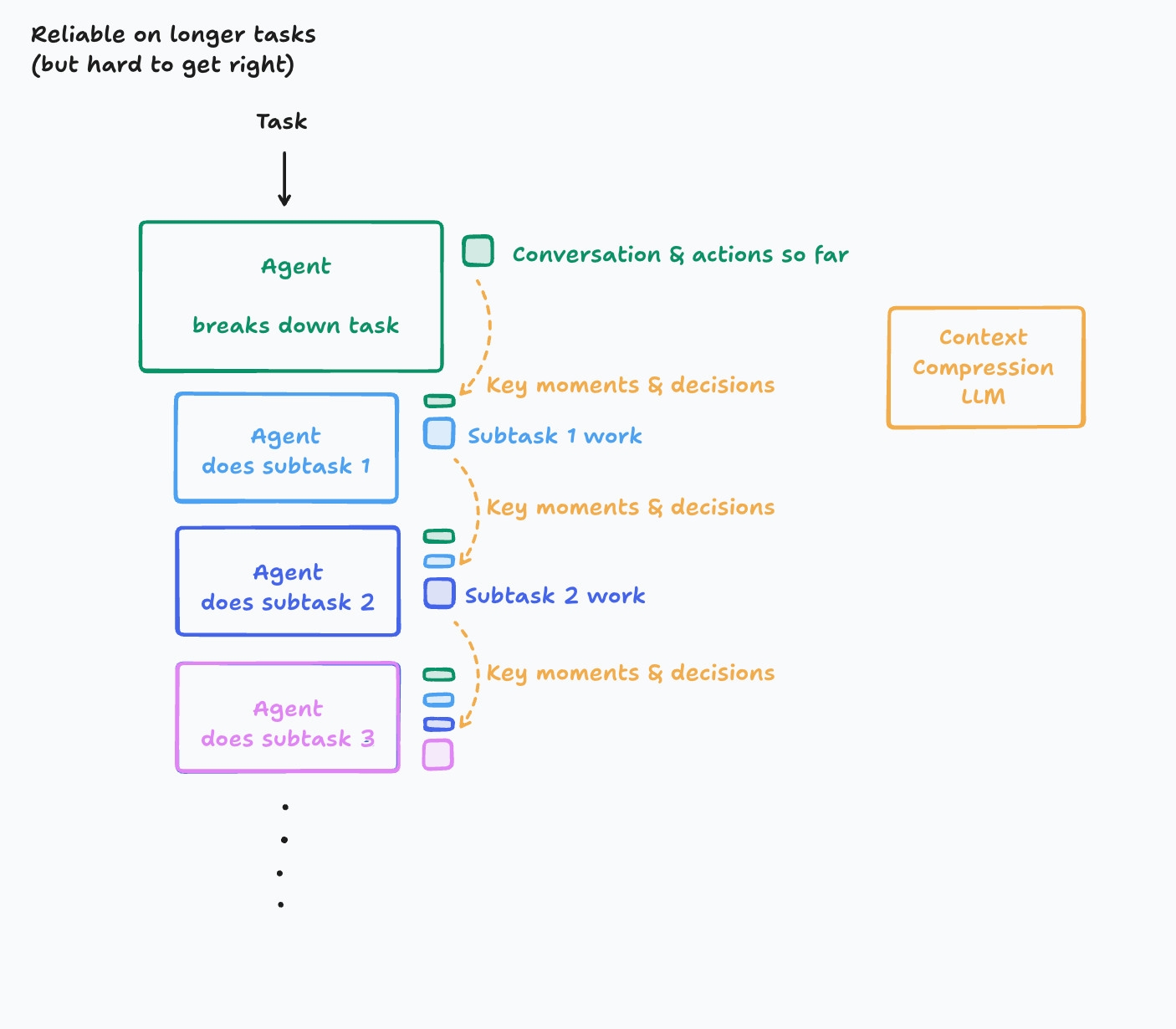
In this world, we introduce a new LLM model whose key purpose is to compress a history of actions & conversation into key details, events, and decisions. This is hard to get right. It takes investment into figuring out what ends up being the key information and creating a system that is good at this. Depending on the domain, you might even consider fine-tuning a smaller model (this is in fact something we’ve done at Cognition).
在这个方案中,我们引入一个新的 LLM 模型,其关键目的是将行动和对话的历史压缩成关键细节、事件和决策。要把它做好非常难。 你需要投入精力去弄清楚哪些信息是关键信息,并创建一个擅长此事的系统。根据任务领域的不同,你甚至可以考虑微调一个更小的模型(事实上,我们在 Cognition 就这么做了)。
The benefit you get is an agent that is effective at longer contexts. You will still eventually hit a limit though. For the avid reader, I encourage you to think of better ways to manage arbitrarily long contexts. It ends up being quite a deep rabbit hole!
你得到的好处是一个能有效处理更长上下文的 Agent。不过,你最终还是会达到一个极限。对于有浓厚兴趣的读者,我鼓励你们思考管理任意长上下文的更好方法。这最终会是一个相当深邃的兔子洞!
应用这些原则
If you’re an agent-builder, ensure your agent’s every action is informed by the context of all relevant decisions made by other parts of the system. Ideally, every action would just see everything else. Unfortunately, this is not always possible due to limited context windows and practical tradeoffs, and you may need to decide what level of complexity you are willing to take on for the level of reliability you aim for.
如果你是一名 Agent 构建者,请确保你的 Agent 的每一个行动都知晓系统中其他部分做出的所有相关决策的上下文。理想情况下,每个行动都应该能看到其他所有信息。不幸的是,由于有限的上下文窗口和现实的权衡,这并不总是可能,你可能需要根据你追求的可靠性水平,来决定你愿意承担多大程度的复杂性。
As you think about architecting your agents to avoid conflicting decision-making, here are some real-world examples to ponder:
当你思考如何设计你的 Agent 架构以避免相互冲突的决策时,这里有一些真实世界的例子值得深思:
Claude Code 的子智能体
As of June 2025, Claude Code is an example of an agent that spawns subtasks. However, it never does work in parallel with the subtask agent, and the subtask agent is usually only tasked with answering a question, not writing any code. Why? The subtask agent lacks context from the main agent that would otherwise be needed to do anything beyond answering a well-defined question. And if they were to run multiple parallel subagents, they might give conflicting responses, resulting in the reliability issues we saw with our earlier examples of agents. The designers of Claude Code took a purposefully simple approach.
截至 2025 年 6 月,Claude Code 是一个会衍生子任务的 Agent 例子。然而,它从不与子任务 Agent 并行工作,而且子任务 Agent 通常只负责回答问题,而不编写任何代码。为什么?因为子任务 Agent 缺乏来自主 Agent 的上下文,而这些上下文对于完成回答一个明确定义的问题之外的任何事情都是必需的。而且,如果他们运行多个并行的子智能体,它们可能会给出相互冲突的回答,从而导致我们前面 Agent 示例中看到的可靠性问题。Claude Code 的设计者刻意采取了简单的方法。
“编辑-应用”模型
In 2024, many models were really bad at editing code. A common practice among coding agents, IDEs, app builders, etc. (including Devin) was to use an “edit apply model.” The key idea was that it was actually more reliable to get a small model to rewrite your entire file, given a markdown explanation of the changes you wanted, than to get a large model to output a properly formatted diff. So, builders had the large models output markdown explanations of code edits and then fed these markdown explanations to small models to actually rewrite the files. However, these systems would still be very faulty. Often times, for example, the small model would misinterpret the instructions of the large model and make an incorrect edit due to the most slight ambiguities in the instructions. Today, the edit decision-making and applying are more often done by a single model in one action.
在 2024 年,许多模型在编辑代码方面表现很差。编码 Agent、IDE、应用构建器等(包括 Devin)的普遍做法是使用“编辑-应用模型”。其核心思想是,给一个小模型一段关于你想要更改的 markdown 格式的解释,让它重写整个文件,实际上比让一个大模型输出格式正确的 diff 更可靠。因此,构建者们让大模型输出代码编辑的 markdown 解释,然后将这些解释喂给小模型来实际重写文件。然而,这些系统仍然非常容易出错。例如,小模型常常会因为指令中最细微的含糊不清而误解大模型的指令,从而做出错误的编辑。如今,编辑决策和应用这两个步骤更常由单个模型在一次行动中完成。
多智能体
If we really want to get parallelism out of our system, you might think to let the decision makers “talk” to each other and work things out.
如果我们真的想从系统中获得并行性,你可能会想让决策者们相互“交谈”并解决问题。
This is what us humans do when we disagree (in an ideal world). If Engineer A’s code causes a merge conflict with Engineer B, the correct protocol is to talk out the differences and reach a consensus. However, agents today are not quite able to engage in this style of long-context proactive discourse with much more reliability than you would get with a single agent. Humans are quite efficient at communicating our most important knowledge to one another, but this efficiency takes nontrivial intelligence.
这就是我们人类在意见不合时所做的(在理想世界中)。如果工程师 A 的代码与工程师 B 的代码产生合并冲突,正确的做法是商讨差异并达成共识。然而,今天的 Agent 还无法以这种长上下文、主动对话的方式进行交流,其可靠性并不会比单个 Agent 高出多少。人类在相互沟通我们最重要的知识时效率相当高,但这种效率需要非凡的智能。
Since not long after the launch of ChatGPT, people have been exploring the idea of multiple agents interacting with one another to achieve goals [3][4]. While I’m optimistic about the long-term possibilities of agents collaborating with one another, it is evident that in 2025, running multiple agents in collaboration only results in fragile systems. The decision-making ends up being too dispersed and context isn’t able to be shared thoroughly enough between the agents. At the moment, I don’t see anyone putting a dedicated effort to solving this difficult cross-agent context-passing problem. I personally think it will come for free as we make our single-threaded agents even better at communicating with humans. When this day comes, it will unlock much greater amounts of parallelism and efficiency.
自 ChatGPT 发布后不久,人们就一直在探索多个 Agent 相互协作以实现目标的想法 [3][4]。虽然我对 Agent 之间相互协作的长期可能性持乐观态度,但很明显,在 2025 年,让多个 Agent 协同工作只会产生脆弱的系统。决策变得过于分散,上下文也无法在 Agent 之间得到充分共享。目前,我没看到有人投入专门精力去解决这个困难的跨 Agent 上下文传递问题。我个人认为,当我们把单线程 Agent 与人类沟通的能力做得更好时,这个问题自然会迎刃而解。当那一天到来时,它将释放出更强大的并行性和效率。
迈向更普适的理论
These observations on context engineering are just the start to what we might someday consider the standard principles of building agents. And there are many more challenges and techniques not discussed here. At Cognition, agent building is a key frontier we think about. We build our internal tools and frameworks around these principles we repeatedly find ourselves relearning as a way to enforce these ideas. But our theories are likely not perfect, and we expect things to change as the field advances, so some flexibility and humility is required as well.
这些关于上下文工程的观察,仅仅是我们未来可能认为是构建 Agent 的标准原则的开端。还有许多挑战和技术没有在这里讨论。在 Cognition,构建 Agent 是我们思考的一个关键前沿领域。我们围绕这些我们发现自己需要反复重新学习的原则来构建我们的内部工具和框架,以此来强化这些理念。但我们的理论可能并不完美,我们也预期随着领域的发展,情况会发生变化,因此同样需要一些灵活性和谦逊。
We welcome you to try our work at app.devin.ai. And if you would enjoy discovering some of these agent-building principles with us, reach out to walden@cognition.ai
欢迎您在 app.devin.ai 尝试我们的工作。如果您乐于与我们一同探索这些构建 Agent 的原则,请联系 walden@cognition.ai